
1. はじめに
ChatGPTに為替レートを尋ねたら、もっともらしい数字がスラスラと返ってきた。けれどよく調べてみると、その数字はどこにも実在しなかった。そんな経験をしたことはありませんか。日常会話なら笑い話で済みますが、もしこれが銀行や証券会社の窓口で起きたら、笑っていられません。誤った残高、間違った金利、資格のない人が口にしてはいけない投資助言。たった一行のAIの「思い込み」が、お客さんに損をさせ、会社には規制当局からの厳しい指導を招いてしまいます。
このように、AIがもっともらしい嘘を堂々と語ってしまう現象は 「ハルシネーション(幻覚)」 と呼ばれています。大規模言語モデル(LLM)が抱える、最も厄介な弱点です。特に金融のように一つのミスが大きな損害につながる世界では、この性質はとても無視できません。
ところがここ数年、AIに「うっかり嘘」をつかせないための技術が、特許の世界で急速に整いつつあります。その鍵になるのが、RAG(検索拡張生成) と呼ばれる仕組みと、人間オペレータからのフィードバックを学習に取り込むハイブリッド型AI という発想です。
2. なぜLLMは金融で「使いにくい」のか
2-1. もっともらしい嘘が出てしまう仕組み
LLMは、膨大な文章を学習して「次に来そうな単語」を確率的に予測することで文章を作っています。つまり、答えを「知っている」のではなく、それらしく「組み立てている」だけなのです。学習データに載っていない話題を尋ねられても、モデルは黙る代わりに、なんとなく筋の通った文章を作ってしまいます。これがハルシネーションの正体です。
例えるなら、テスト勉強で答えがわからないときに、習ったキーワードを並べてそれらしい答案を書いてしまうのと少し似ています。文章としては流暢でも、事実かどうかは別問題なのです。
2-2. 金融業界の「絶対に間違えられない」事情
一方で、金融業界は「ちょっとした間違い」が大きな問題に直結する世界です。銀行や保険会社、証券会社、決済事業者は、開示義務、プライバシー保護、適合性原則(顧客のリスク許容度に合った商品しか勧めてはいけないというルール)など、さまざまな決まりごとを守りながら、多種多様な商品を扱っています。
ですから、金融の現場でAIに求められるのは「賢いこと」よりも、まず 「間違えないこと」「わからないことは正直に黙ること」 です。当たり前のようでいて、現状のLLMにとっては、これが意外に難しいのです。
2-3. ルールベースAIの限界と、新しい主役RAG
昔のカスタマーサポートAIは、キーワード一致やルールセットで動いていました。「○○という単語が入っていれば××と返す」という方式です。シンプルな質問には強いのですが、表現が曖昧だったり文脈に依存したりする質問には弱く、しかも人間オペレータからのフィードバックを取り込んで学んでいく仕組みもありません。規制やサービスが日々変わる金融業界では、この硬直さがすぐに問題になります。
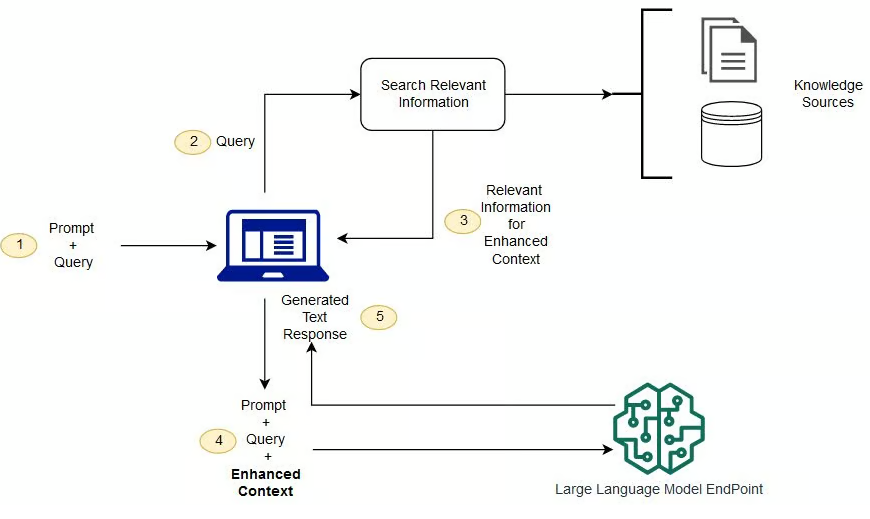
そこで登場したのが、RAG(Retrieval-Augmented Generation:検索拡張生成) です。RAGの考え方はとてもシンプルで、「LLMが答えを作る前に、信頼できる資料を検索してきて、その内容をヒントとしてLLMに渡す」というものです。記憶だけに頼らず、その都度きちんと資料を見てから答える—いわば、図書館の司書さんのような働き方をAIにさせよう、というアイデアです。
3. 特許から見る技術革新
3-1. RAGの土台をつくる特許 ― Microsoft「Response generation using a retrieval augmented AI model」
最初にご紹介するのは、Microsoftが2023年に出願し、2024年10月に公開された米国特許 US20240346256A1「Response generation using a retrieval augmented AI model」 です(発明者:Yinghua Qin氏、出願人:Microsoft Technology Licensing LLC)。
この特許の中心になるアイデアは、LLMが抱える「学習データの中に閉じこもってしまう」という弱点を、外部資料の検索でやわらげるところにあります。具体的には、ユーザーの質問をまず数値ベクトルに変換し、社内ドキュメントやFAQデータベースから「意味的に近い情報」を取り出します。その内容を質問文に添えてLLMに渡すことで、モデルは自分が直接学んでいない情報にも、根拠を持って答えられるようになるのです。
この明細書では「LLMの知識は学習データの範囲内に限られ、しかも一度学習させると簡単には更新できない。だから古い情報や誤情報を堂々と話してしまうことがある」と、ハルシネーションの問題点が率直に述べられています。そして、その解決策としてRAGを位置づけているのが印象的です。事前学習で得た知識(パラメトリック記憶)と、外部の最新資料(非パラメトリック記憶)を組み合わせるこの発想は、これからの「信頼性重視のAI」の基礎とも言える考え方です。
3-2. 検索結果に「答えを根づかせる」特許 ― Google「Generative summaries for search results」
ふたつ目は、Google LLCが保有する米国特許 US11769017B1「Generative summaries for search results」 (登録日:2023年9月26日)です。Google検索で見かける「AIによる要約」機能の中核に近い技術と考えられます。
明細書は、LLMが単独で答えを作るとき、学習データが古かったり不正確だったり、あるいは単純にもっともらしい嘘を生んだりすることを率直に認めています。そのうえで提案されているのが、質問に関連する検索結果のドキュメントを、追加コンテンツとしてLLMに一緒に渡す やり方です。LLMはその追加資料を読み込んだうえで要約を作るので、自分の記憶だけに頼らずに済みます。
さらに面白いのは、過去にユーザーがクリックした検索結果や、似たような質問への過去の応答も手がかりに使い、ユーザーの知識レベルに合わせて「説明しすぎず、足りなさすぎない」要約を返そうとしている点です。そして極めつけは、生成された要約と、その根拠になった検索結果のドキュメントを リンクで結びつける こと。読者は「この答えはどこから来たのか」を、自分の目で確かめられます。これはまさに「答え合わせのできるAI」という発想で、金融や医療のように厳密さが求められる場面に向いた設計と言えそうです。
3-3. 検索結果でLLMを「鍛え直す」特許 ― Google「Fine-tuning LLM(s) using reinforcement learning with search engine feedback」
三つ目は、同じくGoogle LLCの米国特許 US12437016B2「Fine-tuning large language model(s) using reinforcement learning with search engine feedback」 (公開日:2025年10月7日)です。これは、RAGよりもう一歩踏み込み、検索エンジンの結果を「先生役」にして、LLM自体を継続的に鍛え直す 仕組みを描いています。
仕掛けはこうです。まず同じ質問に対して、二通りの答えをLLMに作らせます。一つは検索の助けなしで答えた「素の答え」、もう一つは検索結果をヒントとして渡したうえで答えた「資料に基づく答え」。両者を比べて、もし大きく食い違っていれば、それは「素の答え」が事実から外れていた可能性が高いというサインです。そのギャップから学習用の信号を作り、報酬モデル(良い答えを高く評価する別のAI)を強化学習で訓練し、最終的にLLM自身を「事実重視の応答」をするように微調整していくのです。
ポイントは、これまで人間が手作業で評価していたRLHF(人間フィードバックによる強化学習)の代わりに、検索エンジンという「自動でスケールする情報源」をフィードバック役に置いている点です。今回の起点となった金融分野のハイブリッドAI特許が目指す「継続的に学び続けるAI」という方向性と、見事に重なります。
4. 応用分野・実用化
4-1. 銀行・証券のカスタマーサポート
最も実用が進んでいるのは、銀行や証券会社のカスタマーサポートです。「私の口座の海外送金手数料はいくらですか」「このNISA商品の信託報酬は」といった質問が来たとき、AIが社内規定や商品約款の最新版を検索し、根拠付きで答えてくれます。もし検索した内容との一致度が低かったり、AI自身の確信度が低かったりすれば、無理に答えず、人間のオペレータに引き継ぐ。こうした「分業」が、今回の起点特許やGoogleの一連の特許に共通する理想像です。
CFA協会のレポートも、RAGによる金融文書の自動分析が、コンプライアンス担当者やアナリストの仕事を着実に楽にしつつある、と報告しています。
4-2. 規制対応とコンプライアンス
金融規制は国や地域ごとに違い、しかも頻繁に改訂されます。改訂のたびにAIを学習し直すのは現実的ではありませんが、RAGなら最新の規制文書を検索対象データベースに加えるだけで、AIの「読める資料」をそのまま更新できます。FinNLP 2025の研究でも、金融文書に特化したRAGシステムの体系的な評価が行われ、専門領域での実用性が示されつつあります。
4-3. 投資アドバイスの「適合性チェック」
証券会社では、顧客の投資経験やリスク許容度に合わない商品をすすめてはいけない、という決まり(適合性原則)があります。ハイブリッドAIは、顧客プロファイルと商品データベースを横断的に検索し、「この方にこの商品をご紹介して大丈夫か」を判定したうえで、答えを組み立てます。これは単純な検索ではなく、複数の知識源を組み合わせる マルチアスペクトRAG として、研究が進んでいる領域でもあります。
(https://www.nature.com/articles/s41586-024-07421-0)
5. 課題と展望
5-1. 現在の課題 ― RAGは万能ではない
RAGはハルシネーションをぐっと減らしますが、ゼロにはしません。検索してきた文書そのものが古かったり間違っていたりすれば、LLMはそれを律儀に「正しい根拠」として使ってしまいます。検索の精度、文書の品質チェック、そして生成結果を後から確認する仕組み。この三つをセットで設計しないと、せっかくのRAGも力を発揮しきれません。
5-2. 研究の最前線 ― エージェント型RAGと「答えのブレ」検出
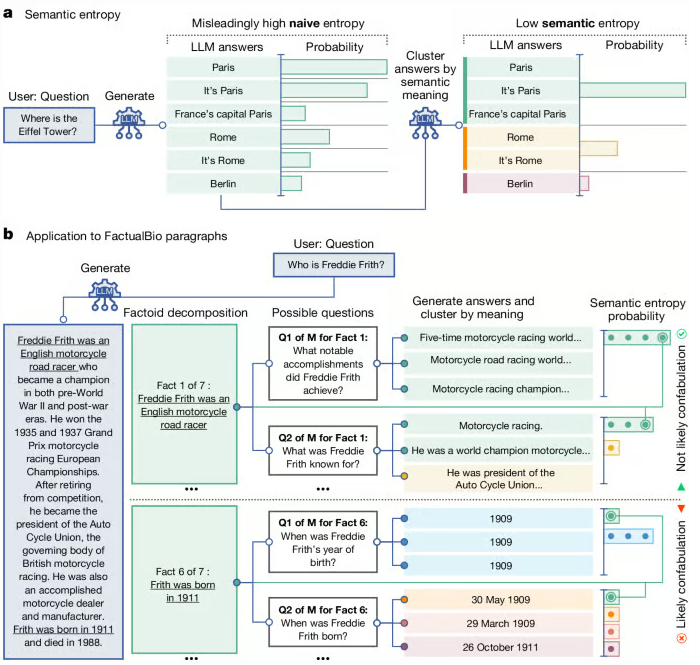
最近の研究は、大きく二つの方向に向かっています。一つは エージェント型RAG で、AIが複数の検索戦略を自分で試しながら、最良の根拠を選び取っていく「Multi-HyDE」のような手法が登場しています。もう一つは、Natureに掲載された セマンティックエントロピー という新しい考え方です。同じ質問にLLMが何度か答えてみて、答えがバラつくほど「自信のない領域」であると判定する、いわば、AIの「迷い」を統計的に拾い上げて、ハルシネーションの兆候を見抜こうという発想です。
5-3. 未来の展望 ― 「正直なAI」が当たり前になる時代へ
これらの特許群が指し示しているのは、AIが「より賢く」進化するというよりも、「より誠実に」進化していく未来です。知っていることは正確に答え、知らないことは「わかりません」と素直に認め、人間のオペレータと協力しながら学んでいく。こうしたハイブリッド型・規制対応型のLLMは、金融を皮切りに、医療、法務、行政といった「ミスが許されない領域」へと広がっていくでしょう。
あわせて読みたい
映像と音声を同じ「意味の地図」の上に並べて扱う、マルチモーダル埋め込みという発想。本記事のRAGが「テキスト同士の意味の近さ」で資料を引き寄せていたのに対し、こちらは画像・音・言葉をまたいで関連性を測る技術です。AIが「意味」をどう捉えているのか、その奥行きを覗いてみたい方におすすめです。

本記事では金融AIの「正確さ」を支える特許を見てきましたが、こちらはAIの「声」を支える特許の世界です。世界中の少数言語に話者の声を届ける多言語TTSは、階層トークン生成という別系統の技術で成り立っています。AIが「言葉そのもの」を扱う技術の幅広さを感じていただける一本です。

6. 結論
LLMの登場は、AIに「言葉の流暢さ」をもたらしました。けれど、流暢さは時に危ういものです。特に金融のように、間違いがそのまま金銭損失や法的責任に結びついてしまう世界では、流暢な嘘ほど扱いにくいものはありません。
本記事で見たMicrosoftとGoogleの三つの特許は、それぞれ「検索で補強する」「検索結果で根拠づける」「検索フィードバックで鍛え直す」という三段構えで、AIに正直さを取り戻させようとしています。さらに、今回の起点となった金融分野のハイブリッドAI特許は、これらに加えて 人間オペレータのフィードバック と 強化学習 を組み合わせ、規制と顧客サービスが日々動き続ける現場でも、信頼できる答えを提供し続ける仕組みを描いています。
「賢いAI」から「信頼できるAI」へ。この静かな転換は、今この瞬間も、特許の世界で着実に進んでいます。次に銀行のチャットボットと会話する機会があったら、その向こう側でどんな技術が「うっかり嘘」を防いでくれているのか、少しだけ想像してみてください。きっと、これまでとは違った景色が見えてくるはずです。
関連アイテム
1時間でわかる LLMとRAGのしくみ:非エンジニアでも読み切れる、ベクトル検索とLangChainの実践入門(橘 圭介 著/Kindle版)
タイトル通り、非エンジニアでも1時間で読み通せる入門書です。ChatGPTに「検索する力」を与えるRAGの仕組みを、図解つきでやさしく解説しており、本記事で触れたベクトル検索や埋め込みといったキーワードが、よりはっきりと頭に入ってきます。
テーマに近い関連する特許文献
- US20240346256A1「Response generation using a retrieval augmented AI model」, Microsoft Technology Licensing LLC, 2024-10-17公開.
- US11769017B1「Generative summaries for search results」, Google LLC, 2023-09-26登録.
- US12437016B2「Fine-tuning large language model(s) using reinforcement learning with search engine feedback」, Google LLC, 2025-10-07公開.
- US20240394512A1「GENERATIVE AI(ハルシネーション検出)」, 2024-11-28公開.
記事を作成するにあたり参考にした文献
- Tonmoy, S. M. T. I. et al. “A Comprehensive Survey of Hallucination Mitigation Techniques in Large Language Models.” arXiv:2401.01313, 2024. https://arxiv.org/abs/2401.01313
- “Enhancing Financial RAG with Agentic AI and Multi-HyDE.” arXiv:2509.16369, 2025. https://arxiv.org/html/2509.16369v1
- “A Multi-aspect RAG System for Financial Filings Question Answering.” arXiv:2504.14493, 2025. https://arxiv.org/html/2504.14493v2
- “Assessing RAG System Capabilities on Financial Documents.” FinNLP 2025 (ACL Anthology). https://aclanthology.org/2025.finnlp-2.9.pdf
- Farquhar, S. et al. “Detecting hallucinations in large language models using semantic entropy.” Nature, 2024. https://www.nature.com/articles/s41586-024-07421-0
- “What is RAG? – Retrieval-Augmented Generation Explained.” AWS公式. https://aws.amazon.com/what-is/retrieval-augmented-generation/
- “Retrieval Augmented Generation (RAG): Enhance LLMs with Factual Data.” IBM. https://www.ibm.com/think/architectures/patterns/genai-rag
- “What is Retrieval-Augmented Generation (RAG)?” Google Cloud. https://cloud.google.com/use-cases/retrieval-augmented-generation
- “RAG for Finance: Automating Document Analysis with LLMs.” CFA Institute. https://rpc.cfainstitute.org/research/the-automation-ahead-content-series/retrieval-augmented-generation
コメント