
1. はじめに
数年前まで、AIが生成する音楽は「メロディらしきもの」が断片的につながった、どこか不自然な合成音でした。それが今では、テキストでと指示するだけで、コーラスもベースもドラムも整った数分のトラックが出てきます。音声合成も同じです。話者の声色や息づかいまで真似て、まるで本人がスタジオで読み上げたかのような音声が、数十秒のサンプルから生まれます。
この急激な進化を支えているのが、「音や映像を“言葉”のように扱って予測する」という発想の転換です。画像でも音でも動画でも、いったん離散トークンという小さな単位に分解してしまえば、文章を生成する大規模言語モデルとほぼ同じ仕組みで扱える。そして、長くて複雑な信号を破綻なく作り続けるために、「時間方向のフレーム」と「フレーム内の深さ」という二段構えで予測していく。これが、今世界中の研究室と特許出願で進んでいる潮流です。
今回は、その背景にある技術を、特許3件を軸にやさしく読み解いていきます。
2. 音を「言葉のように」扱う仕組み
2-1. 連続信号を“単語”に変える ― ニューラルオーディオコーデック
音声や音楽は本来、連続的に変化する波形です。1秒間に2万回以上値が変わるアナログ的な信号を、そのままAIで予測するのは現実的ではありません。そこで登場したのが、ニューラルネットワークで音を圧縮して「離散的な番号の並び」に変換するニューラルオーディオコーデックという考え方です。
Googleが2021年に発表した SoundStream は、その代表例です。エンコーダ・量子化器・デコーダの3つを一気通貫で学習させ、スマートフォンのCPU上でもリアルタイムに動作するレベルまで圧縮効率を高めました。3 kbpsという極低ビットレートでも、12 kbpsのOpusを上回る音質を示したと報告されています。
ここで音が「言葉化」されます。波形は、たとえば「34番、12番、198番、…」といった整数列に変換され、AIから見れば有限種類の“単語”の並びになるのです。
2-2. 一段では足りない ― 残差ベクトル量子化(RVQ)という工夫
ただし、音を一回の量子化で十分な解像度に落とすのは難しい。語彙が大きくなりすぎてしまい、学習が破綻します。そこで使われるのが残差ベクトル量子化(Residual Vector Quantization, RVQ)です。
一段目で大まかに量子化し、その「誤差(残差)」を二段目でさらに量子化し、また残差を三段目で…という具合に、何段も積み重ねていく。SoundStreamでは最大80段までの構成が試され、各段が小さなコードブックを持つことで、巨大な語彙を持たずに高い解像度を実現しました。
例えるなら、絵を描くときに「最初に大きな筆で全体の色を置き、次に中筆で形を整え、最後に細筆で輪郭をなぞる」のと同じです。各段は前の段で取りこぼした情報だけを担当するので、効率よく細部まで再現できます。
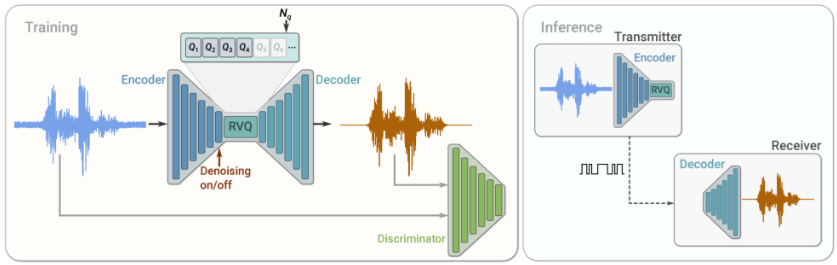
2-3. 「フレーム」と「深さ」― 階層トークン生成という設計思想
ここからが本題です。RVQで得られる音のトークンは、二次元の格子のような構造を持ちます。横軸は時間(フレーム)、縦軸は深さ(段)です。1フレームあたり数段から数十段のトークンが積み重なっています。
これをそのまま一列に並べて予測しようとすると、トークン数が膨大になりすぎて、長い音をモデル化できません。そこで考え出されたのが、「フレームを担当するモデル」と「深さを担当するモデル」を分担させるやり方です。
- まず上位のフレームモデルが、各時間フレームを代表するトークンを順番に予測する
- 次に下位の深さモデルが、そのフレーム代表トークンを手がかりに、同じフレーム内の細かいトークンを埋めていく
この二段構えにより、長時間の構造(楽曲の起承転結や話の文脈)は上位モデルが、瞬間ごとの音色や倍音の細部は下位モデルが、それぞれ得意分野で受け持つことができます。Google Researchの AudioLM が示した「semantic token → coarse acoustic token → fine acoustic token」という階層構造は、まさにこの考え方の典型例で、複数のTransformerを連結して段階的に音を生成します。

3. 特許から見る技術革新
3-1. テキストから「構造ある音楽」を生む特許
ひとつ目に取り上げるのは、Google LLCが出願した US20180190249A1「Machine Learning to Generate Music from Text」 です(発明者:Dominik Roblek, Douglas Eck、公開日:2018年7月5日)。
この特許の核心は、テキストから音楽を生成する際に、入力テキストから構造的特徴(structural features)を抽出する「特徴抽出器」と、その特徴に基づいて楽曲を生成する機械学習オーディオ生成モデルを組み合わせる点にあります。詩や会話、SNSの投稿など、入力テキストをセグメントに分割し、韻律やムード、主題といった構造情報を取り出してから音楽生成に渡すことで、従来手法に欠けていた「曲としてのまとまり」、つまりグローバルな一貫性を確保しようという発想です。
この特許自体はまだ階層トークン生成という言葉を使ってはいません。しかし「テキストの構造を先に取り、それを条件としてオーディオ生成モデルに渡す」という多段アーキテクチャは、後年のAudioLMやMusicLMが採用する「上位の構造トークン → 下位の音響トークン」という階層化の出発点になった、極めて重要な布石です。
3-2. 「離散トークンを拡散モデルで生む」特許
ふたつ目は、DeepMind Technologies Ltdが出願した WO2024068781A1「Discrete token processing using diffusion models」(公開日:2024年4月4日)。
拡散モデルといえば、画像生成で有名な「ノイズを少しずつ除去して絵を浮かび上がらせる」あの手法です。ところが拡散モデルは本来、連続的な値を扱うのが得意で、テキストや音声トークンのような離散的な記号列には素直に適用できません。
この特許が提案するのは、離散トークンそのものをぼかすのではなく、トークンに対応する“埋め込みベクトル(連続値)”の空間で拡散・逆拡散を行うという巧妙な切り分けです。具体的には、
- 入力シーケンスから初期の連続潜在表現を作る
- 拡散モデルが逆拡散を繰り返してこの潜在表現を更新していく
- 最終的に得られた潜在ベクトルに学習済みのデエンベディング行列を掛け、各トークンのスコアを算出して、最尤のトークンを選ぶ
という手順で、連続空間で滑らかに推論しつつ、出力は離散トークン列に着地させます。明細書では、テキスト→音声(text-to-speech)、音声→テキスト、エージェントの行動シーケンス生成など、多様なユースケースが想定されており、まさにマルチモーダル系列生成を志向した特許といえます。
冒頭で触れた「フレームモデル+深さモデル」の階層生成と、この拡散ベースの離散トークン生成は、「言語モデル型」と「拡散型」という対照的な二つの潮流ですが、どちらも「離散トークン」という共通の出口を持っています。今後、両者が組み合わさったハイブリッド構成が出てくることは、ほぼ確実視されています。
3-3. 「ラベルなしデータから音声モデルを育てる」特許
三つ目は、Google LLCが出願した WO2024015140A1「Unsupervised data selection via discrete speech representation for automatic speech recognition」(公開日:2024年1月18日)。
タイトルは音声認識(ASR)に関するものですが、本質的な仕掛けは生成AIにも直結します。要点は次の3ステップです。
- ラベルなしの音声データを量子化し、離散トークン列に変換する
- ターゲットドメイン用の言語モデルと汎用言語モデルでスコアを比較し、ドメイン関連スコアを算出する
- スコアが高いデータだけを選び出し、それを使ってASRモデルを事前学習する
ここで重要なのは、「音声を離散トークンにしてしまえば、テキストと同じように言語モデルで“それらしさ”を測れる」という点です。SoundStreamで音が単語化されたのと同じ発想で、データ選別までも言語モデル流に行える。
階層トークン生成モデルを実用化する上で最大のボトルネックは、莫大な学習データの「質」をどう担保するかです。この特許は、その問いに対して「離散化+言語モデル的スコアリング」という汎用的な答えを示した点で、後続の生成AI研究への波及効果が大きいと考えられます。
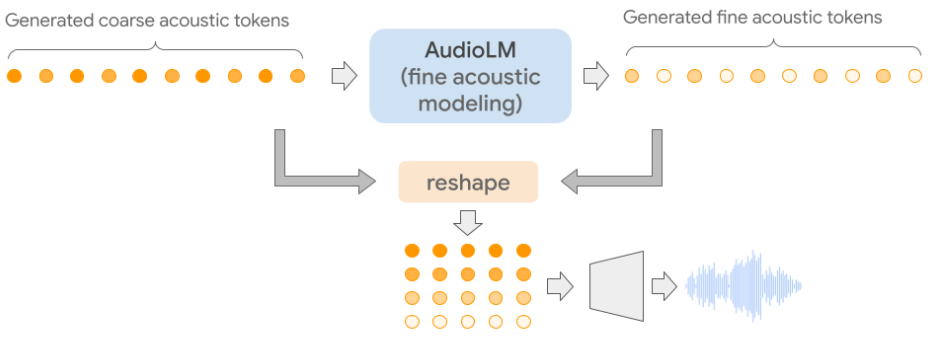
4. 応用分野・実用化
4-1. 音楽生成と作曲支援
最も派手な応用先は、テキストからの音楽生成です。Meta社の MusicGen は、単一のTransformer言語モデルにEnCodecの離散トークンを食わせ、テキストやメロディ条件に従って高品質な楽曲を生成します。インターリーブと呼ばれるトークン並べ替えパターンを使い、複数の段(深さ)のトークンを巧みに織り交ぜることで、本来なら階層的に分けて推論しなければならない処理を一段のTransformerでまかなっているのが特徴です。
Google Researchの MusicLM も、テキスト条件付き音楽生成で著名で、自然言語プロンプトから数分の楽曲を作ります。作曲家にとっては、デモ作成・サウンドスケッチ・BGM試作の時短ツールとしてすでに実用段階に入りつつあります。
4-2. テキスト音声合成(TTS)とボイスクローン
階層トークン生成は、TTS分野でも主役になりつつあります。Microsoftの VALL-E は、ニューラルオーディオコーデックの離散トークンを言語モデル的に予測することで、わずか数秒のサンプルから話者の声を再現するゼロショットTTSを実現しました。後継の VALL-E 2 では、人間レベルに迫る自然さと頑健性が報告されています。
低リソース言語への展開という観点でも、これらの階層トークン技術は欠かせないインフラになりつつあります。
4-3. 動画・3D・行動シーケンスへの拡張
階層トークン生成のもう一つの強みは、音だけでなく動画、3D、ロボットの行動列といった、他の時系列マルチモーダルデータにそのまま応用できる点です。動画なら「フレーム単位の高位トークン」と「フレーム内のパッチ単位トークン」という二段構成、ロボティクスなら「全身の姿勢トークン」と「関節別の細粒トークン」という分担が考えられます。
WO2024068781A1の明細書が、テキスト、音声、エージェントの行動列まで広く対象として記載していたのは、まさにこの汎用性を見越したものといえるでしょう。
5. 課題と展望
5-1. 現在の課題 ― 計算コストと長尺化
階層トークン生成は強力ですが、課題も少なくありません。第一に計算コスト。フレームモデルと深さモデルを連鎖させると、推論時のメモリ消費と遅延がふくらみます。MusicGenが「単段+インターリーブ」というアプローチで階層化を回避しようと試みたのも、この計算負荷との戦いの一端です。
第二に長尺生成での一貫性。30秒のクリップは作れても、3分の楽曲や30分のポッドキャストに拡張すると、話題が逸れたり、雰囲気がドリフトしたりする問題が残ります。
5-2. 研究の最前線 ― 連続と離散のハイブリッド
最前線では、「離散トークン+言語モデル」と「連続表現+拡散モデル」を組み合わせるハイブリッド設計が模索されています。WO2024068781A1のように、連続な潜在空間で拡散を回しつつ最後だけ離散に落とす手法もあれば、逆に離散トークンの上で拡散的なリファインを行う手法もあります。
また、Meta社の EnCodec や、Multi-Band Diffusionによるデコーダ強化など、コーデック側の進化も止まりません。Meta AI Audiocraft 階層トークン生成は、生成側と表現側、双方の改良が両輪となって進化していく分野です。
5-3. 未来の展望 ― 「マルチモーダル系列」という統一視点
今後の本命は、音・映像・テキスト・行動を、すべて同じ離散トークン空間に並べてしまう統一モデルだと考えられます。フレームモデルが「次に何が起こるか」を予測し、深さモデルが「その瞬間に何が見え、何が聴こえ、誰が何を言うか」を埋める。映画の脚本も、楽曲も、ロボットの動作も、同じアーキテクチャから出力される時代が、特許出願の動きを見るかぎりそう遠くないところまで来ています。
特許翻訳者の立場からみると、明細書中の「frame token」「depth token」「codebook index」といった術語をどの日本語に当てるかは、まだ訳語が揺れている領域です。用語選定の精度が、特許の権利範囲を直接左右するフェーズに入ったと感じます。
あわせて読みたい
階層トークン生成は、音声・音楽だけでなく、動画や多言語音声合成といった隣接領域にも広がりつつあります。本記事で触れきれなかった応用面については、以下の関連記事もあわせてご覧ください。
画像・音声・テキストを共通の埋め込み空間で扱う研究が、いま動画解析の世界を大きく塗り替えています。本記事の「離散トークン化」と裏表の関係にある、マルチモーダル表現学習の最新動向を解説しています。

階層トークン生成の応用先として最も実用が進んでいるのが、テキスト音声合成(TTS)です。少量のサンプルから話者の声を再現するボイスクローン技術と、低リソース言語への展開について掘り下げています。

6. 結論
「フレーム」と「深さ」という二軸で時系列データを階層化し、離散トークン列として言語モデル流に予測する。この設計思想は、もはや音声生成だけの話ではありません。音楽、ナレーション、動画、ロボット制御――すべての時系列マルチモーダル生成に、共通の骨格を与えつつあります。
今回取り上げた3件の特許は、それぞれ「テキストから構造ある音楽を生む」「離散トークンを拡散モデルで生む」「ラベルなしデータから階層モデルを育てる」という、異なる角度から階層トークン生成の土台を支えています。明細書を一つひとつ丁寧に読むと、各社が次の5年でどこに陣地を築こうとしているのか、その輪郭がはっきり見えてきます。
関連アイテム
大規模言語モデルは新たな知能か ― ChatGPTが変えた世界(岡野原大輔 著/岩波科学ライブラリー)
日本のAI研究を牽引する岡野原大輔氏が、ChatGPTの仕組みをやさしくまとめた一冊。本記事で何度も出てきた「トークン」「言語モデル流の予測」が数式なしで腑に落ち、音声・音楽・動画への応用が同じ原理でつながっていることが見えてきます。
参考文献
テーマに近い関連する特許文献
- Google LLC, “Machine Learning to Generate Music from Text,” US20180190249A1, 2018-07-05. https://patents.google.com/patent/US20180190249A1/en
- DeepMind Technologies Ltd, “Discrete token processing using diffusion models,” WO2024068781A1, 2024-04-04. https://patents.google.com/patent/WO2024068781A1/en
- Google LLC, “Unsupervised data selection via discrete speech representation for automatic speech recognition,” WO2024015140A1, 2024-01-18. https://patents.google.com/patent/WO2024015140A1/en
記事を作成するにあたり参考にした文献
- Borsos, Z. et al., “AudioLM: a Language Modeling Approach to Audio Generation,” Google Research Blog. https://research.google/blog/audiolm-a-language-modeling-approach-to-audio-generation/
- Zeghidour, N. et al., “SoundStream: An End-to-End Neural Audio Codec,” Google Research Blog / arXiv:2107.03312. https://research.google/blog/soundstream-an-end-to-end-neural-audio-codec/
- Agostinelli, A. et al., “MusicLM: Generating Music From Text,” arXiv:2301.11325, 2023. https://arxiv.org/abs/2301.11325
- Copet, J. et al., “Simple and Controllable Music Generation (MusicGen),” arXiv:2306.05284 / Meta AudioCraft. https://audiocraft.metademolab.com/musicgen.html
- Défossez, A. et al., “High Fidelity Neural Audio Compression (EnCodec),” arXiv:2210.13438 / Meta AI. https://ai.meta.com/blog/audiocraft-musicgen-audiogen-encodec-generative-ai-audio/
コメント