
1. はじめに
ほんの数年前まで、「文章を入力するだけで写真のような絵が出てくる」という体験はSFの世界でした。ところが2022年以降、Stable DiffusionやDALL-E、Imagenといったサービスが次々と登場し、いまや誰もが数秒でイラストや写真風画像を作れる時代になっています。
しかし、ここで一つ素朴な疑問が浮かびます。AIは本当に「絵を描いている」のでしょうか? その内側では、ノイズを消したり、文と画の意味を結びつけたりと、想像以上に巧妙な仕掛けが動いています。
2. テキストから画像が生まれる仕組み
2-1. 「ノイズから絵が浮かび上がる」という発想
現在の主流である拡散モデル(Diffusion Model)は、一見すると不思議な学習方法をとります。まず元画像に少しずつノイズを加えて完全な砂嵐に近づけ、次にその逆方向、つまり砂嵐からノイズを引いていく過程を学習させるのです。

この発想を理論として整え、高品質な画像生成が可能であることを実証したのが、Ho らによる2020年のDDPM(Denoising Diffusion Probabilistic Models)論文でした。学習が安定しにくかった旧来のGAN(敵対的生成ネットワーク)に比べ、拡散モデルは学習が安定し、しかも多様な画像を生成できるという利点があり、以降のテキスト画像生成の基盤になりました。
2-2. 「文の意味」と「画の意味」を結ぶCLIP
ただし、ノイズを取り除く力だけでは「猫」と入力したのに犬が出てくる、ということが起こり得ます。鍵を握るのが、文と画像を同じベクトル空間に写し込む技術で、その代表がOpenAIのCLIP(Contrastive Language-Image Pre-training)です。
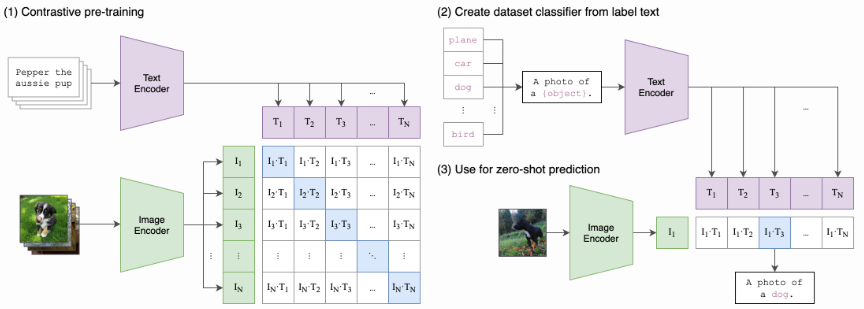
CLIPは、ウェブから集めた大量の「画像とそのキャプション」の組をペアとして近づけ、関係のない組は遠ざけるように学習します。これにより、「夕焼けの海辺を歩く犬」のような自然言語と、その画像の特徴量を直接比較できるようになりました。テキストから画像を生み出すモデルの多くは、このCLIPあるいは類似のテキストエンコーダを「言葉の通訳」として組み込んでいます。
2-3. 計算負荷を激減させた「潜在空間」というトリック
初期の拡散モデルには弱点もありました。512×512ピクセルの画像をピクセル単位で扱うと、計算量が膨大になるのです。
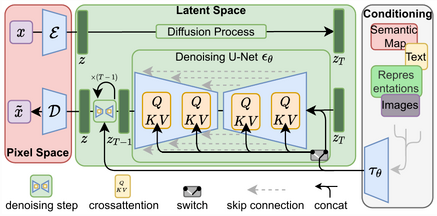
これを解決したのが、Rombach らによる潜在拡散モデル(Latent Diffusion Model, LDM)です。一度オートエンコーダで画像を小さな潜在表現に圧縮し、その潜在空間の中で拡散・逆拡散を行うことで、画質をほぼ落とさずに計算コストを大幅に削減しました。これが現在のStable Diffusionの心臓部であり、家庭用GPUでも動作する画像生成AIを実現した立役者でもあります。
3. 特許から見る技術革新
3-1. OpenAIの「階層的テキスト条件付き画像生成」(US11922550B1)
OpenAIに付与された米国特許 US11922550B1 は、DALL-E 2の中核に近い技術を押さえています。テキストをエンコーダに入力してテキスト埋め込みを得たのち、第1のサブモデルでそれに対応する画像埋め込みを生成し、第2のサブモデルでこの画像埋め込みから最終的な出力画像を生成する、という二段構えのアーキテクチャです。
この「先にテキストから画像の意味ベクトルを作り、その後で実画像にデコードする」という分業は、多様性と意味的整合性を両立させる工夫として知られています。
3-2. Adobeの「拡散モデルの効率的ファインチューニング」(US20240185588A1)
巨大な拡散モデルを業務で使うとき、最大の悩みは「自社ブランドのキャラクターや特定スタイルをどう覚えさせるか」です。再学習にコストをかけすぎれば、これまで覚えた知識が壊れてしまいます(破滅的忘却)。
Adobeの US20240185588A1 は、この課題に対しアテンション層、特にクロスアテンションの射影マッピングだけを更新するという解を示しました。残りのパラメータは凍結したまま、新しい概念の少数の画像例だけでファインチューニングする手法で、メモリ効率と忘却耐性を両立できます。
3-3. サムスンの「拡散モデルの逐次カスタマイズ」(US20240311693A1)
スマートフォンなどデバイス側でAIを動かすことを見据えるサムスンは、別のアプローチで競争に参入しています。米国特許 US20240311693A1 では、初期重みと過去の重みデルタを保持したまま、新しい概念に対する追加の重みデルタだけを生成し統合する仕組みを提案しています。
低ランク適応(LoRA的なパラメータ)を用い、過去データを残さずに概念を順次追加できるため、プライバシー保護と継続学習に強いというのが大きな特徴です。
これら3件を並べてみると、OpenAIは骨格となるアーキテクチャ、Adobeはクリエイター向けの効率的カスタマイズ、サムスンはデバイス上での継続学習と、各社が役割分担をするように知財を押さえつつあることが分かります。
4. 応用分野・実用化
4-1. クリエイティブと広告
最も分かりやすい応用は、広告ビジュアル、商品ラフ、コンセプトアートなどの制作現場です。

GoogleのImagenシリーズも、写実性とテキスト整合性を打ち出し、ブランドキャンペーンや映像制作のラフ案作りで使われ始めています。Adobe特許のように「自社ブランドの一貫性」を学習させる技術は、広告領域では特に重要です。
4-2. 医療・科学・産業ビジュアライゼーション
学術論文や医療現場では、説明用イラストや模式図の作成にも使われ始めています。希少疾患のイメージ図、製薬の仕組み解説、地球科学のシミュレーション可視化など、人手では時間がかかる図版を補助する用途です。テキスト・トゥ・イメージ生成技術全般のサーベイ論文でも、医療・科学領域への応用が継続的に拡大していると整理されています。
4-3. パーソナライズと「自分専用モデル」
サムスン特許やAdobe特許に共通するのが、「個人やブランドの少数サンプルから新しい概念を覚えさせる」というニーズへの応答です。家族写真をもとに作品風アバターを作る、自社ロゴを保ったままバナーを量産するといった用途は、いずれもこの系統の技術が支えています。スマートフォンやクラウド上で「自分専用に育っていく画像生成AI」が現実のものになりつつあります。
5. 課題と展望
5-1. 現在の課題
技術が広く使われるにつれ、課題もはっきりしてきました。第一に著作権と学習データの問題です。学習に使われた画像の権利関係をめぐり、Imagenを含む大規模モデルに対して訴訟も起きており、透明性と権利処理の枠組み作りが急がれています。
第二に、現実との誤差の問題です。指の本数、文字、物理法則の整合性など、人間が一目で違和感を持つ細部はいまだに苦手領域です。第三に、ディープフェイクなど悪用リスクもあり、出力画像のウォーターマーキングや来歴管理の標準化が議論されています。
5-2. 研究の最前線
研究の最前線では、(a)ステップ数を大幅に減らした高速サンプリング、(b)動画やマルチモーダルへの拡張、(c)3Dシーンや物理整合性を意識した生成、(d)小型・端末側モデル、といったテーマが急速に進んでいます。サーベイ論文によれば、2021年以降の数年間で、テキスト画像生成はGAN中心から拡散モデル中心へ完全に主流が入れ替わったと整理されており、いまも変化のスピードは衰えていません。
5-3. 未来の展望
これから注目すべきは、「画像を作るAI」から「意図を理解して設計するAI」へのシフトです。単なる絵作りを超え、技術文書の図、製品プロトタイプ、教育コンテンツなど、目的志向のビジュアル生成へと用途が広がっていくでしょう。特許の世界でも、モデルの構造そのものよりも、ユーザーとの対話設計や用途特化の制御方法に争点が移っていくと見られます。
あわせて読みたい
画像生成AIが「絵を作る」技術なら、こちらはAIが「図を読み解く」技術の特許動向です。文章生成側の最前線として、ぜひあわせてご覧ください。

テキストと画像をつなぐCLIPの発想は、動画解析にも応用されています。音と映像を同じ空間に埋め込むことで、SNSのトレンドがどう生まれるのかを読み解いた回です。

6. 結論
テキストから画像を生み出すAIは、もはや「面白いツール」の枠を超え、広告・科学・教育・産業設計を横断する汎用ビジュアル生成インフラへと姿を変えつつあります。その内側では、ノイズを取り除く拡散モデル、文と画を結ぶCLIP、計算を圧縮する潜在空間という三つの仕掛けが噛み合い、特許の世界では OpenAI、Adobe、サムスンといった企業がそれぞれ異なる切り口で陣地を確保しています。
特許翻訳の現場から見ると、この分野は用語が日々アップデートされるため、原文の一語の選び方が訳文の意味を大きく左右します。最新の研究と特許を継続的に読み解きながら、技術の本質を日本語で正確に伝えることこそ、これからの翻訳者に求められる役割だと感じています。
関連アイテム
世界一やさしいChatGPT&画像生成AI(インプレスムック)
ChatGPTと画像生成AIの基本が、図版多めの誌面でまとめられています。本記事で触れた拡散モデルやテキスト・トゥ・イメージの考え方を、まずは手を動かしながら体験してみたい方にぴったりの一冊。専門用語に身構えず、画像生成AIの世界に第一歩を踏み出すための導入書としておすすめします。
参考文献
テーマに近い関連する特許文献
- US11922550B1「Systems and methods for hierarchical text-conditional image generation」OpenAI Opco LLC, 2024-03-05 Google Patents
- US20240185588A1「Fine-tuning and controlling diffusion models」Adobe Inc., 2024-06-06 Google Patents
- US20240311693A1「Sequential customization of text-to-image diffusion models」Samsung Electronics Co Ltd, 2024-09-19 Google Patents
- US20190286950A1「Generating a digital image using a generative adversarial network」 Google Patents
記事を作成するにあたり参考にした文献
- Ho, J., Jain, A., Abbeel, P. (2020) “Denoising Diffusion Probabilistic Models,” arXiv:2006.11239 arXiv
- Radford, A. et al. (2021) “Learning Transferable Visual Models From Natural Language Supervision,” arXiv:2103.00020 arXiv
- Rombach, R. et al. (2022) “High-Resolution Image Synthesis with Latent Diffusion Models,” arXiv:2112.10752 arXiv
- Saharia, C. et al. (2022) “Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding (Imagen),” arXiv:2205.11487 arXiv
- Zhang, N. et al. (2024) “Text-to-Image Synthesis: A Decade Survey,” arXiv:2411.16164 arXiv
- Google DeepMind, “Imagen — Text-to-Image Models” 公式ページ Google DeepMind
- OpenAI / GitHub, “CLIP: Contrastive Language-Image Pre-training” 公式リポジトリ GitHub
コメント